
Neste post irei mostrar como fazer o scraping de um produto da loja da Amazon buscando as informações mais importantes do produto.
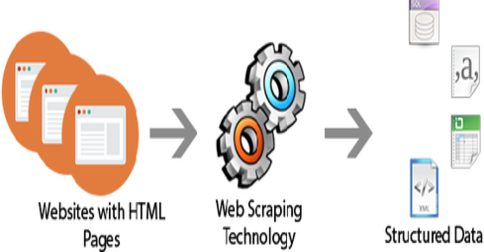
O que será usado
A biblioteca usada
A biblioteca usada será o BeautifulSoup, que é bem conhecida por quem costuma fazer web crawler de algum site usando python. Esta biblioteca ajuda a organizar e formatar o HTML buscado.
Instalação
Os passos para instalação são:
- apt-get update
- apt-get install python-bs4 Mais informações
Execultando o BeautifulSoup
Primeiramente, teremos que fazer um request no site desejado, e com a função urlopen acessar o conteúdo da pagina HTML, e então iremos colocar este conteúdo em um objeto BeautifulSoup:
import urllib
from bs4 import BeautifulSoup
url = "https://www.amazon.com.br/Loja-Tudo-Jeff-Bezos-Amazon/dp/8580574897/ref=sr_1_1?ie=UTF8&qid=1518971948&sr=8-1&keywords=loja+de"
pagina = urllib.urlopen(url)
ObjBS = BeautifulSoup(pagina.read())
print(ObjBS.title)
O resultado deste codigo será o titulo da pagina.
Buscar informações especificas da pagina
O BeautifulSoup tem funções que nós ajudam a buscar informações especificas das quais queremos. Nós usaremos apenas uma:
findAll()
Com o findAll() podemos filtrar elementos especificos nas paginas HTML, apartir de atributos de tags.
Para saber qual é a tag do elemento que queremos, basta selecionar o que queremos, e com o botão direito ir em inspecionar elemento:
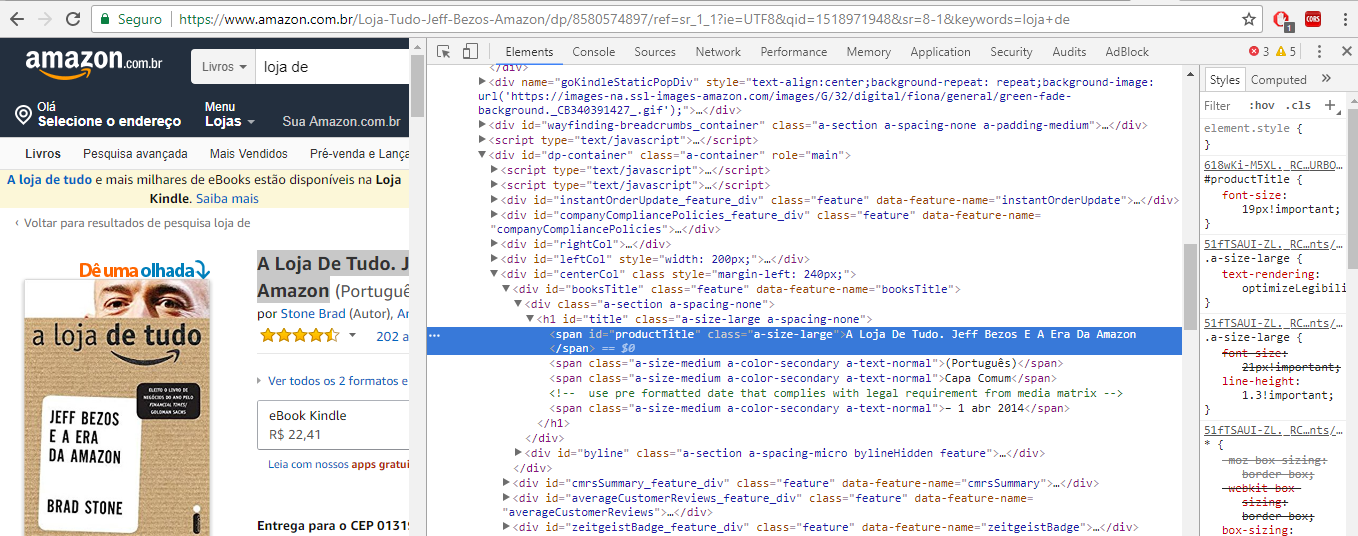
Neste caso queremos o id da tag span:
ObjBS .findAll("span", {"id": "productTitle"});
Isso ira buscar todas as tag span que tenha o id productTitle. Para garantir que vamos pegar a primeira ocorrencia, podemos tratar assim:
Aux = ObjBS .findAll("span", {"id": "productTitle"});
Titulo = Aux[0].text
- Para pegar o preço
Preco = ObjBS .findAll("span", {"class": "a-size-base a-color-price a-color-price"});
- Pegar a Descrição
Descricao = ObjBS .findAll("div", {"class": "productDescriptionWrapper"});
Resultado Final Código https://github.com/CassioPimentel/ScrapingAmazon
Console
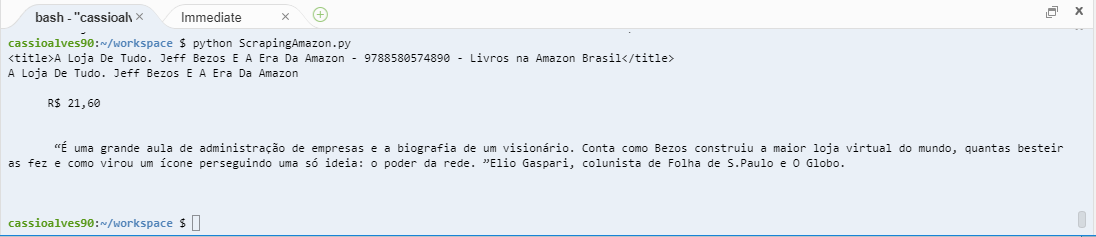
Espero que tenham gostado.